
Self‑Hosted AI Chat on Ubuntu: Open WebUI plus Ollama Setup
If you have been looking for a way to run your own AI chatbot without sending your data to any third-party service, learning how to install Open WebUI with Ollama on Ubuntu is the right move. This setup gives you a full ChatGPT-like interface running entirely on your own server; your conversations stay private, your models stay local, and you stay in control.
In this guide, you will learn everything from installing Docker and Ollama to pulling your first model and putting the whole thing behind HTTPS.
Table of Contents
System Requirements to Install Open WebUI with Ollama on Ubuntu
Running local AI models requires real hardware. Here is what you need to install Open WebUI with Ollama on Ubuntu:
| Component | Minimum | Recommended |
|---|---|---|
| RAM | 8 GB for small models only | 16 GB+ for 7B models |
| CPU | Any modern x86_64 | AVX512-capable such as Intel 11th Gen or AMD Zen4 |
| Disk | 20 GB free | 50 GB+ to store multiple models |
| GPU | Not required | NVIDIA GPU greatly speeds up inference |
| OS | Ubuntu 20.04+ | Ubuntu 22.04 or 24.04 LTS |
Note: For CPU-only servers, 7B parameter models like Llama 3 or Mistral 7B run well with 16 GB of RAM. If you plan to use larger models or serve multiple users at once, a dedicated AI hosting server with a GPU will make a huge difference.
Once you are done with the system requirements, proceed to the following steps to start your setup.
Step 1: Update Your Ubuntu Server
First, you must update your system, which makes sure all existing packages are current before adding anything new:
sudo apt update && sudo apt upgrade -yStep 2: Install Docker Engine on Ubuntu
Open WebUI is officially recommended to run inside Docker. Docker keeps the app and all its dependencies in one clean container, making updates and rollbacks easy.
Install required packages:
sudo apt install ca-certificates curl gnupg lsb-release -yAdd Docker’s official GPG key and repository:
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] \
https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullInstall Docker Engine:
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -yAdd your user to the Docker group so you do not need sudo every time:
sudo usermod -aG docker $USER
newgrp dockerVerify the Docker installation:
docker --versionYou should see a Docker version number.
Step 3: Install Open WebUI with Ollama on Ubuntu
This is the core step where you install Open WebUI with Ollama on Ubuntu. There are two methods you can use:
- A quick single-container method.
- A Docker Compose method for production.
Option A: Quick Single Command Best for Testing
For this method, you need Ollama running on the host. To install it, you can use the command below:
curl -fsSL https://ollama.com/install.sh | shThe install script sets up Ollama as a systemd service that starts automatically. Verify it is running:
sudo systemctl status ollamaThen, use the following command to run Open WebUI in Docker and connect it to Ollama running on the host machine:
docker run -d \
-p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:mainThe -v open-webui:/app/backend/data flag creates a persistent Docker volume so your chat history and settings survive container restarts or updates.
Once it starts, open http://YOUR_SERVER_IP:3000 in your browser to verify it.

Expose Ollama to Docker
When you install Ollama directly on the host, and Open WebUI is running in a container, you may need to tell Ollama to listen on all interfaces so Docker can reach it.
Edit the Ollama systemd service:
sudo systemctl edit ollamaAdd these lines to the file:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"Security note: This setting is only for allowing the Docker container to reach Ollama on the same host. Make sure port 11434 is not open to the public internet at the firewall level. For safe public exposure of the Ollama API, use a reverse proxy with HTTPS and authentication instead.
Save and restart the service:
sudo systemctl daemon-reload
sudo systemctl restart ollamaNow the Docker container can reach Ollama at http://host.docker.internal:11434.
Option B: Use Docker Compose Recommended for Production
If you want both Ollama and Open WebUI managed together with persistent storage, Docker Compose is the better method.
Create a project folder and a compose file with the commands below:
mkdir ~/open-webui-stack && cd ~/open-webui-stack
nano docker-compose.ymlPaste the following configuration:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
tty: true
pull_policy: always
volumes:
- ./ollama-data:/root/.ollama
ports:
- "11434:11434"
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
depends_on:
- ollama
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- ./webui-data:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"Save and close the file. Start the stack:
docker compose up -dThe OLLAMA_BASE_URL=http://ollama:11434 environment variable tells Open WebUI exactly where to find Ollama inside the Docker network. The volumes (./ollama-data and ./webui-data) store all model files and chat data on your server’s local disk, so nothing is lost if you restart or update the containers.
Step 4: Pull Your First AI Model
Once Ollama is running, you need to download a model before you can chat. Open a terminal and run:
ollama pull llama3.2This downloads Meta’s Llama 3.2 model, about 2 GB for the 3B version. Other popular options you can use include:
ollama pull mistral # Mistral 7B — fast and capable
ollama pull gemma3 # Google Gemma 3
ollama pull qwen2.5 # Alibaba Qwen 2.5To see all models you have installed, you can use:
ollama lsIf you are using the Docker Compose setup, pull models inside the Ollama container:
docker exec -it ollama ollama pull llama3.2Tip: If you want to fine-tune models or work with heavier workloads, check this guide on Llama 3 fine-tuning on a GPU VPS.
Step 5: First Login and Admin Setup
To access Open WebUI, open your browser and go to:
http://YOUR_SERVER_IP:3000The first time you load Open WebUI, it asks you to create an admin account. Fill in a name, email, and password; this becomes the admin user for the entire instance.
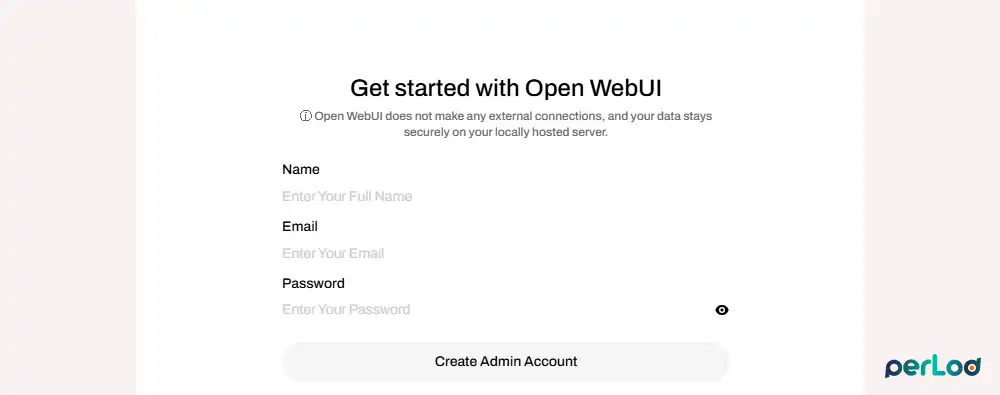
After logging in, go to Admin Panel → Settings → Connections.
You must make sure the Ollama API URL shows http://localhost:11434 for Option A or http://ollama:11434 for Option B.
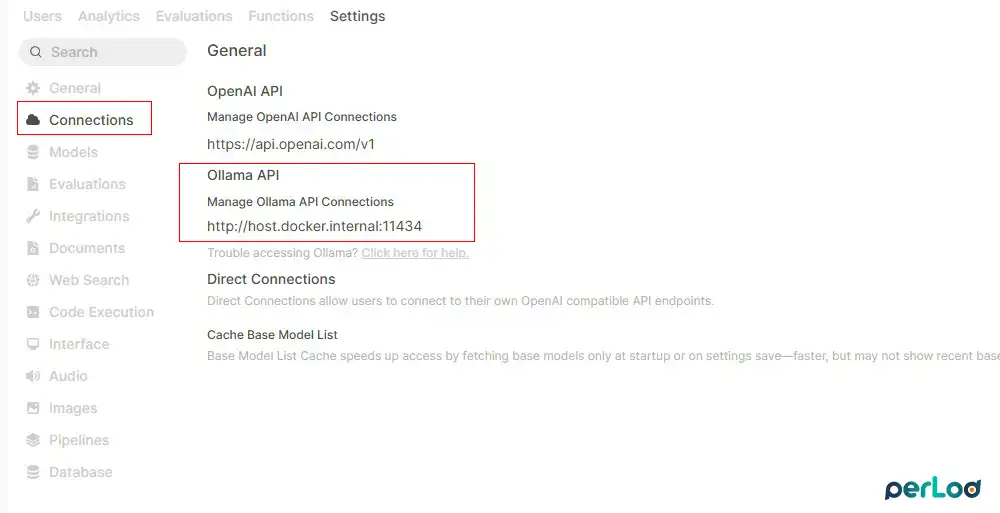
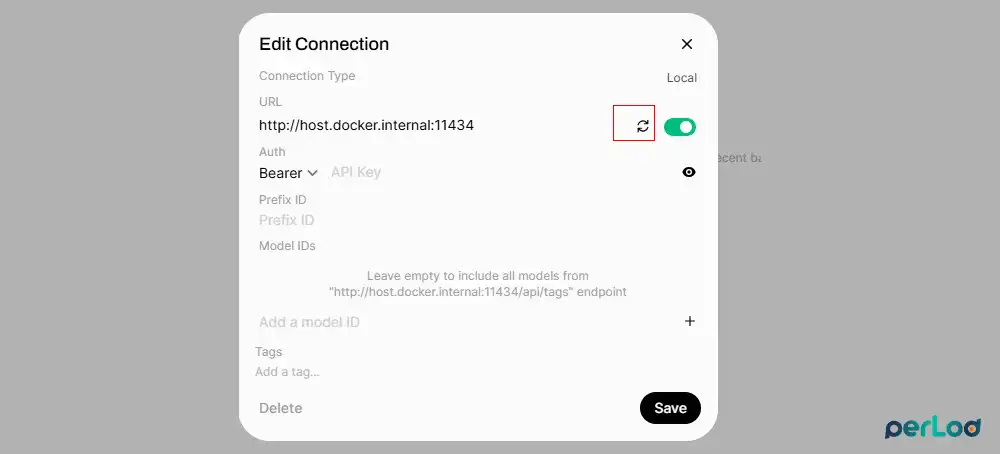
Under the Ollama API, click the small gear icon (settings) to the right of the toggle. A panel opens with the Ollama connection details and URL.
Click that circular arrow; if Open WebUI can talk to Ollama, it will briefly show a success state.
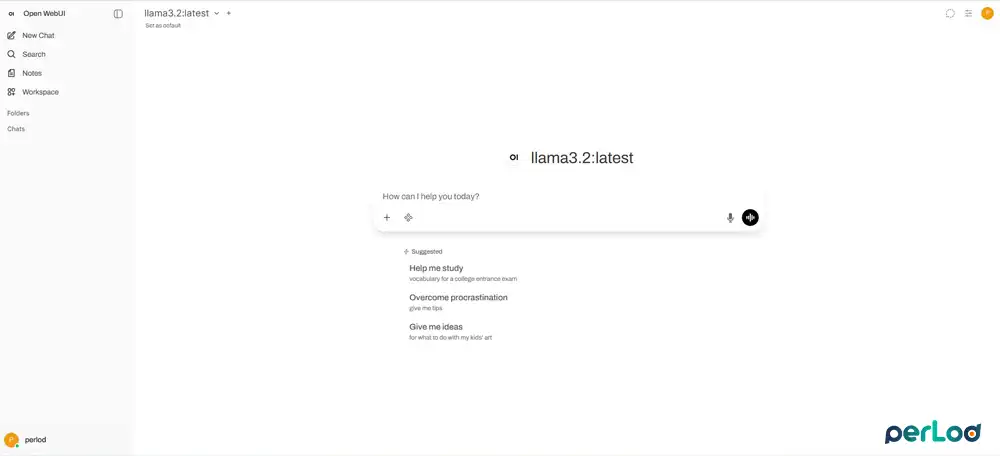
Once you are done, go to the chat window, select a model, and pick the model you just pulled. You can now start chatting with your private AI.
If you want to see the upstream reference commands or alternative install methods, see the official Open WebUI Docs.
Understand Persistent Storage in Open WebUI with Ollama Installation with Docker
One of the most important things to get right when you install Open WebUI with Ollama on Ubuntu is making sure your data does not disappear when Docker restarts.
Here is what each volume stores:
| Volume | What It Contains |
|---|---|
open-webui:/app/backend/data | Chat history, user accounts, settings, and uploaded documents |
./ollama-data:/root/.ollama | Downloaded model files. Can be several GB each |
If you used the single Docker command (Option A), Docker creates a named volume automatically. You can find it with:
docker volume inspect open-webuiIf you used Docker Compose (Option B), data is stored in ./ollama-data and ./webui-data folders right in your project directory, which is easy to back up with a simple rsync or tar command.
Set Up HTTPS with Nginx For Multi-User or Public Access
Running Open WebUI over plain HTTP is fine on a local network, but if you want to access it from outside or share it with a team, HTTPS is required. Also, modern browsers block microphone access for voice features without a secure connection. The easiest way is to use Nginx with Certbot Let’s Encrypt.
Install Nginx and Certbot:
sudo apt install nginx certbot python3-certbot-nginx -yCreate an Nginx site config:
sudo nano /etc/nginx/sites-available/open-webuiPaste this configuration with your actual domain:
server {
listen 80;
server_name your.domain.com;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_buffering off;
proxy_read_timeout 300s;
}
}Save and close the file. Enable the site and get your SSL certificate:
sudo ln -s /etc/nginx/sites-available/open-webui /etc/nginx/sites-enabled/
sudo nginx -t
sudo systemctl reload nginx
sudo certbot --nginx -d your.domain.comCertbot automatically edits your Nginx config to add HTTPS and sets up auto-renewal. The proxy_buffering off line is important; without it, AI responses stream incorrectly. The proxy_read_timeout 300s gives the model enough time to generate long answers.
If you do not have a domain, you can use Cloudflare Tunnel for a free zero-config HTTPS setup, or just keep it on HTTP for internal use.
Updating Open WebUI
When a new version of Open WebUI comes out, updating is straightforward.
For Option A (single container):
docker pull ghcr.io/open-webui/open-webui:main
docker stop open-webui
docker rm open-webui
# Run the original docker run command againFor Option B (Docker Compose):
cd ~/open-webui-stack
docker compose pull
docker compose up -dYour data in the volumes is not touched during updates.
Conclusion
By following this guide, you can install Open WebUI with Ollama on Ubuntu and get a fully functional setup to run private AI chat on your own infrastructure.
For a simple personal setup, a single Docker command and a pulled model are all you need. For a team or production environment, Docker Compose, persistent volumes, and an Nginx reverse proxy with HTTPS give you the best foundation.
Your data never leaves your server, you choose which models to run, and you scale the hardware to match your needs. If you are running CPU-only workloads, a flexible Linux VPS with 16+ GB of RAM handles smaller models. If you need faster inference for heavier models or multiple users, a dedicated AI hosting plan with GPU support is the better choice.
FAQs
Do I need a GPU to install Open WebUI with Ollama on Ubuntu?
No. Ollama works on the CPU only. It will be slower, but models like Llama 3.2 3B or Mistral 7B run well on a server with 16 GB of RAM.
Is Open WebUI free to use?
Yes. Open WebUI is fully open-source and free to self-host. You only pay for the server it runs on.
Can I connect Open WebUI to OpenAI or other cloud APIs?
Yes. Open WebUI supports OpenAI-compatible APIs, Anthropic, and others alongside Ollama.
